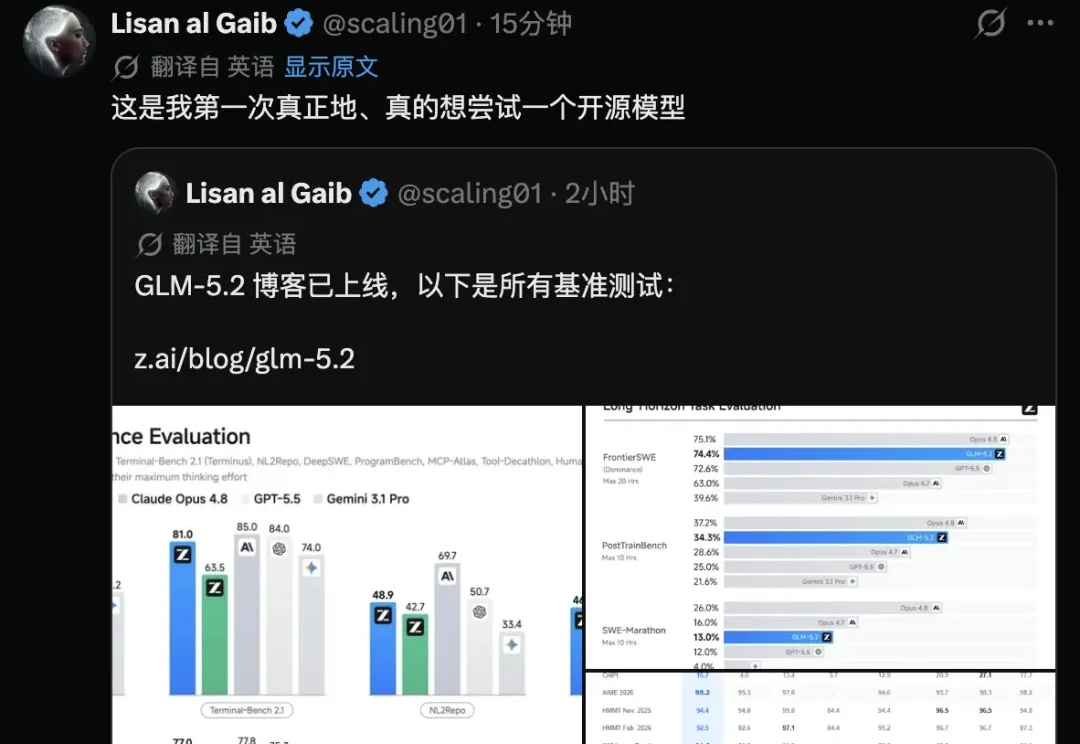
刚刚,OpenAI 放出满血版 GPT-5.5-Cyber!剑指 Claude Mythos 5
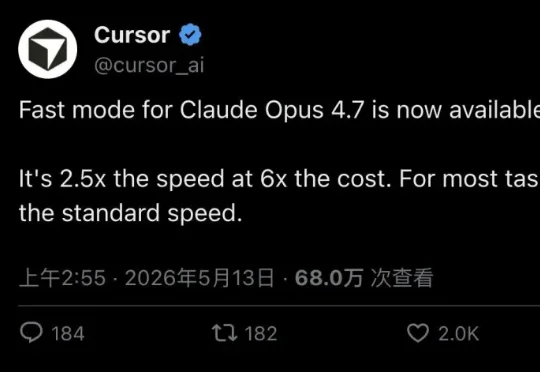
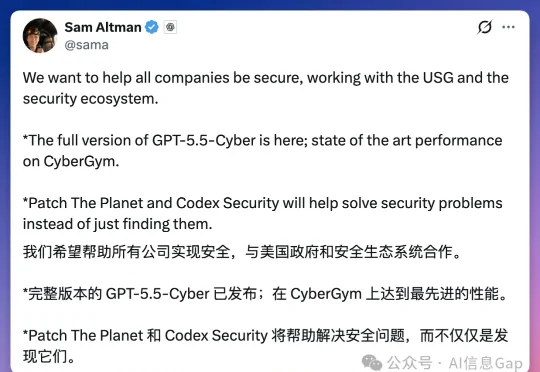
刚刚,OpenAI 放出满血版 GPT-5.5-Cyber!剑指 Claude Mythos 5就在刚刚,OpenAI 直接放出了满血版 GPT-5.5-Cyber。CyberGym 安全评测排行榜,GPT-5.5-Cyber 得分 85.6%,单模型最高分。Claude Mythos 5 第二,83.8%。Claude Opus 4.7 排末尾,73.1%。
来自主题: AI资讯
9325 点击 2026-06-23 09:09